Por razones que no tardan en ser obvias es necesario iniciar este artículo con un poco de historia, una que se remonta cerca de 10 años atrás al inicio de la Era 3D en los videojuegos. La aparición de los primeros engines tridimensionales obedece a la siguiente cadena de eventos:
- una nueva familia de procesadores más rápida y más eficiente (Pentium, Pentium MMX, Pentium II),
- la necesidad de diferenciarse y destacarse de los diferentes productos disponibles en el mercado,
- el establecimiento del Windows 95 y el DirectX como una plataforma de desarrollo casi ideal.
Una característica de estos primeros engines tridimensionales que merece ser destacada es que eran en un principio por software (en el sentido que utilizaban el mismo CPU que cualquier otra aplicación/programa), pero no tardaron en aparecer los híbridos que podían aprovechar de la presencia de una tarjeta aceleradora de gráficos.
 |
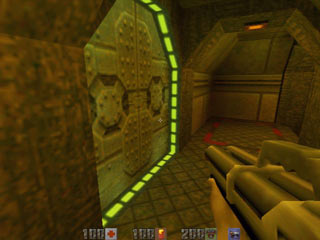 |
| Capturadas de pantalla de HomeWorld: Cataclysm y Quake II, juegos que ofrecen sistemas gráficos por software y hardware. |
Juegos como Quake II y HomeWorld fueron los primeros en ofrecer tecnología 3D, en ambos casos el engine trabajaba por software y los contados afortunados(as) que contaban con una tarjeta aceleradora podían verlo todo con más detalle y con algunos efectos visuales adicionales. A medida que el mercado para tarjetas GPU crece, baja costos y mejora los desarrolladores ceden ante la gran cantidad de extras que tales tarjetas ofrecían --al menos en comparación con sólo software--. En una generación la mayoría de los engines deja de incluir modo software pero en cambio poseen mayor detalle, cantidad de efectos y presencia de animaciones. A partir de aquí se puede decir "y lo demás es historia".
Antes de continuar con el artículo en si y para evitar cierta ambigüedad en el término vale decir que a la hora de la verdad un engine 3D por software es equivalente a decir que trabaja utilizando sólo las capacidades de procesamiento del CPU (un procesador de propósito general), mientras que un engine 3D por hardware (o acelerado por hardware) aprovecha de extras especializados que hoy en día conocemos como tarjetas gráficas y cuyo componente principal es el GPU (un procesador de propósito --casi-- específico).
El debate sobre las ventajas de uno u otro tiene más que nada un fundamento económico tanto de parte de quienes los fabrican como de quienes los consumen (utilizan). Para los primeros, bueno, son su fuente de trabajo; para los segundos son un gasto adicional que de ser posible sería interesante poder evitar. El presente artículo omite este delicado aspecto del tema y se enfoca sobre como la evolución actual de los CPU podría, a la larga --entre cinco y diez años--, hacer innecesaria la presencia de un GPU para procesar engines 3D. Al menos según y como hoy trabajan estos procesadores dedicados y según como hoy entendemos y funcionan los sistemas gráficos 3D.
Tal y como lo expongo en el artículo Hardware: El Siguiente Paso. La virtual muerte, en ese entonces, de los engines gráficos basados en software (o con modo software) se debe a: (1) cuestiones del momento no fácilmente diferenciables, (2) condiciones del mercado, (3) el sorpresivo salto evolutivo dado por los GPU, y (4) la entrada en escena del Windows 95 y el DirectX. A este último punto se puede atribuir el que el CPU tenga más trabajo que hacer y por lo tanto cuente con menos cíclos disponibles para ser usados por el engine gráfico, sin olvidar que la mejora visual atribuida a la presencia de una tarjeta de aceleración ya era demasiado distinguible de lo que se podía presentar sin su asistencia.
No hay que menospreciar el hecho de que una vez que los engines gráficos en tres dimensiones agarraron la atención del mercado aparecieron una buena cantidad de empresas que ofrecían alternativas de aceleración gráfica (3Dfx, ATI, S3, Matrox, Nvidia). Sin embargo, al principio y por al menos una generación esto complico el esquema a las desarrolladoras porque tenían que hacer sus productos específicamente compatibles con tal o cual GPU. Al final la lucha termina en gran medida gracias a estándares como el OpenGL y el DirectX que permiten al software ignorar los detalles del hardware siempre y cuando pueda realizar determinadas instrucciones (funciones, operaciones). Esto y la dinámica de mercado que dicto que era imposible mantener a tantas compañías en el negocio nos trae al estado en el que se encuentra la industria en cuestión actualmente.
Hoy en día no utilizar un engine 3D es prácticamente visto como algo extraño e inusual, aunque no faltan quienes lo hacen por ser diferentes o para acceder a una mayor cantidad de usuarios potenciales (con ordenadores un poco "primitivos"). Otro motivo nace del reciente incremento en la presencia de Internet en el mundo y el poder aprovechar de tecnologías Web y ofrecer aplicaciones que no son muy pesados de descargar y ejecutan con fluidez (Java, Flash). Todos los engines tridimensionales modernos requieren y aprovechan al máximo de cualquier hardware de aceleración disponible. Sin embargo esto parece que va cambiar (aunque a partir de cuando o gracias a que tecnología en particular está todavía por verse).
 |
 |
| Una capturada de JavaGamePlay(com) un sitio Web con cantidad de juegos basados en Java, y otra del juego Dofus un MMORPG en español que trabaja con Flash MX. |
A partir de este punto el artículo es más que nada especulación --muy bien-- educada, y deducciones basadas en la información disponible. Llegado el momento puede que la realidad que nos rodee no sea exactamente igual, o muy parecida pero es más que probable que tenga algo, o mucho, de lo que expongo a continuación.
Actualmente todo apunta a que existe la posibilidad de agarrar al CPU y al GPU y fusionarlos en una sola entidad. El concepto detrás GPGPU (General Purporse Graphics Processing Unit, Unidad de Procesamiento Gráfico de Propósito General) es la alternativa opuesta: la de otorgar a un GPU la capacidad de actuar como un microprocesador capaz de hacer otras tareas y no sólo aquellas relacionadas con renderizar. Por ejemplo, Nvidia tiene su CUDA (Compute Unified Device Architecture) que es un API de extensión al lenguaje C que permite a ciertas funciones utilizar los stream processors; y ATI trabaja en conjunto con la Universidad de Stanford para el proyecto Folding@Home (relacionado a la investigación de proteínas).
Dejando de lado cualquier extensión proporcionada por hardware con cierta afinidad al tema de acelerar el renderizado (sea por método de rasterización como ahora o por Ray Tracing) hay que considerar dos hechos básicos: (1) tanto Intel como AMD-ATI siguen aumentando el número de núcleos de procesamiento en sus CPU, (2) tanto Intel como AMD-ATI tienen planeado incluir nuevas microinstrucciones que ayudan a procesar tareas relacionadas con multimedia, audio, y en especial gráficos 3D mucho más rápido (un aspecto importante es el incremento en el número de operaciones de punto flotante que se puede procesar).
Para el tema en análisis no menos importante es el hecho de que ambas compañías están cambiando a un bus de transferencia de datos que --en su primera entrega-- triplica la velocidad del actual conocido como FSB (Front Side Bus). Intel con su QuickPath Interconnect (QPI) y AMD con HyperTransport en su versión 3.0. Así mismo mejoran la manera en que trabajan las caché e incluyen una mayor cantidad en sus nuevos microprocesadores. También hay que destacar que están optimizando la gestión de memoria RAM y optimizando las cosas para la más rápida DDR3 SDRAM (pros: duplica la velocidad de transferencia comparada con la DDR2, acepta de 512MB a 16 GB por tarjeta/SIM, consume menos energía y posee una lógica de funcionamiento optimizada; cons: no es compatible con el socket de la DDR2 y todavía es más costosa; no es lo mismo que la GDDR3 de tarjetas gráficas).
El plan a corto plazo de Intel tiene a su arquitectura Larrabee como una otra opción a la actual noción que se posee sobre las tarjetas gráficas o los gráficos integrados. Su característica más destacada es un conjunto de instrucciones especializadas para procesar vectores que se agrupan en un VPU. Además aprovecharía de otras tecnologías, como el bus QPI y el concepto de microarquitectura modular, para, en principio, reemplazar ciertas tareas realizadas por un GPU o en todo caso complementarlo. Todavía no está muy claro este tema, excepto por la aclaración de que no se trata de un giro de 180 grados hacia el uso de Ray Tracing (o el trabajo con), ni es un reemplazo de las tarjetas gráficas (que se sepa). Si todo sigue su plan sabremos más sobre esta arquitectura a fin de año.
 |
| Una imagen de la película The Incredibles de Pixar y Disney, su renderizado utiliza métodos Ray Tracing con el detalle que se trata de material precomputado no en tiempo real. |
Dejando a un lado las grandes novedades hay que enfocarse en las dos microarquitecturas para CPU que Intel posee en su mesa, Nehalem y Sandy Bridge. Lo más destacado de ambas es su uso del nuevo tipo de bus QPI que es más rápido y eficiente, el que cada core pueda manejar memoria a gusto sin restringir su acceso por otros núcleos, y la inclusión de un nuevo conjunto de instrucciones que permiten acelerar cantidad de procesos, entre ellos operaciones sobre punto flotante y vectores. Nehalem extiende el SSE4 introducido en Penryn (la generación anterior) con 7 nuevas instrucciones, y Sandy Bridge incluye por primera vez el conjunto AVX (Advanced Vector Extensions). Todo el reciente show sobre estas tecnologías y el método Ray Tracing para engines 3D viene de dejar demasiadas imaginaciones a rienda suelta, y el que casualmente éste método tenga como base el uso de vectores y sea ideal para aprovechar ejecución en paralelo.
Personalmente, y es una noción aceptada por muchos expertos en el área, considero que la cosa apunta a que --por ahora-- la idea es desarrollar y evolucionar de manera paulatina complementos y extensiones a la presencia de un GPU, con un aparente objetivo a mediano plazo que sería el reemplazarlo sin por ello absorberlo en el procesador central como es lo que se asume más comúnmente. En cualquier caso, se mantendría la tecnología presente con que trabajan los engines 3D o a lo mucho desarrollando implementaciones híbridas con Ray Tracing. Después de todo la verdadera pregunta aquí, en relación a las tecnologías multi-core, es ¿qué hacer con tanto poder de procesamiento?
La practicidad de toda éste avance es nulo si llegado el momento no se tiene motivos reales para adquirir un CPU con 16 o más núcleos (que están a cosa de un año para salir al mercado). Son contados los juegos que pasan del 50% de uso en un Core2-Duo, idealmente en un Core2-Quad no deberían superar el 25% de uso. Aún con la crecida constante de la complejidad en un videojuego sus necesidades de procesamiento no se incrementan al mismo ritmo que el de la salida de nuevos CPU, con el detalle agregado que existe un límite en los primeros de que tan complejos pueden ser y que tanto pueden aprovechar el paralelismo real sin por ello dificultar las cosas en extremo para diseñadores, programadores y hasta jugadores[1].
El volúmen de cíclos de procesador disponibles se ha incrementado a tal punto durante este último par de años, y da para mucho más, que tareas como el procesamiento de audio en una tarjeta independiente está en miras de ser innecesario. Este hecho es respaldado por como Creative Labs (los de SoundBlaster) está en pleno proceso de llevar toda la lógica de gestión de señales de sus tarjetas dedicadas a una aplicación de software (el X-Fi MB). Lo que es más interesante es que todo el proceso de lidiar con decenas de canales, depurar señal, añadir efectos y demás consume apenas un 5% de la capacidad total de un CPU actual (léase Core2-Duo).
A corto plazo, según su modelo la Era de Tera, la idea de Intel en su forma más básica es contar con hileras de núcleos de procesamiento generales (los que hoy en día tenemos y referimos como CPU), complementados por un número pequeño de núcleos de soporte que trabajan con instrucciones específicas a diferentes tareas. Por ejemplo, capacidad adicional para procesar números reales, para realizar operaciones vectoriales gráficas como las usadas por Ray Tracing, operaciones gráficas generales, manipulación de señales de audio, etcétera. Siendo está una de las posibles alternativas para dar mejor uso, y mayor uso, a tanto núcleo de procesamiento.
El más reciente prototipo funcional para investigaciones de Intel consta de 80 núcleos de procesamiento y alcanza a ejecutar 1 Teraflop (un trillón de instrucciones matemáticas por segundo, o un millón de millón, o 1'000.000'000.000, o 1x10 a la 12va potencia), para ello consume 62 watts de corriente y ocupa apenas el tamaño de una estampilla (unos 275mm cuadrados). La primera vez que se logro computar 1 Teraflop fue en 1996 utilizando la ASCI Red Supercomputer construida por Intel para Sandia National Laboratory, requería cerca de 10.000 Pentium Pro que consumían más de 500 kilowatts, y ocupaba como 2.000 pies cuadrados (unos 600 mts cuadrados), esto sin contar la energía requerida para evitar que el lugar se caliente demasiado.
 |
 |
| Foto y diagrama artístico de la súpercomputadora ASCI Red, la primera en calcular 1 Teraflop en 1996. |
Existe una diferencia crítica entre incluir nuevas instrucciones, SSE4 o AVX, y núcleos de soporte especializados como el VPU de Larrabee. Las instrucciones es como incluir un nuevo lenguaje y como tal mientras sepa como hablarlo puedo decir lo que quiera, mientras que en el segundo caso, siguiendo la misma metáfora, son frases pregrabadas que sirven sólo para decir ciertas cosas en particular pero más rápido (por decirlo así).
|