Durante el proceso de escribir este artículo me tope con que existe mucha información y comentarios sobre todo lo analizado, especulado y expuesto. Sin embargo, note que algunas especificaciones y novedades cambian dependiendo la fecha del artículo de referencia o según lo que tal o cual ejecutivo de relaciones públicas desee priorizar de los productos o tecnologías que expone. También ocurre que las ideas o conceptos cambian entre uno y otro momento, o que las descripciones de determinada arquitectura o modelo sufren alteraciones en el tiempo. El punto es, todo lo presentado aquí se basa en gran medida en la información y datos disponibles hasta el momento de puesta en línea del artículo; de existir una necesidad imperativa para corregir algo la misma se dará a la brevedad posible.
En un artículo pasado, Hardware: Ahora sí un Paso Adelante (14/11/2007) para ser más específico, comente sobre cómo las tecnologías multi-core (de Intel o AMD-ATI) establecían un nuevo modelo en hardware que permitiría al software alcanzar límites insospechados, más aún cuando se habla de software de entretenimiento electrónico. El artículo en cuestión termina expresando un temor personal sobre el camino que podría tomar la actual evolución tecnológica y el caso de excepción que podría hacerla aceptable. Recientes anuncios tanto de Intel como AMD-ATI acaban confirmando mis peores temores, con el detalle que quizá también cumplan con la excepción que podría convertir algo que se preferiría no llegar a ver en algo que se espera con ansiedad.
Recientemente en el artículo 2008: El Estados de los Juegos Para PC expongo y en cierta medida analizo los comentarios realizados por Alex St. John (cofundador y CEO de WildTangent) en una entrevista realizada por ExtremeTech respecto a su punto de vista sobre la tecnología y los juegos de ordenador. Una de sus respuestas destaca como él se siente muy esperanzado con las propuestas para el futuro inmediato hechas por las dos productoras de microprocesadoras del momento, lo único que aclara es que "[p]ara que llegado el momento las cosas ocurran como uno espera las mismas tienen que ser hechas de la forma adecuada".
Debido a mi mayor familiaridad con el entorno de Intel a partir de ahora el artículo lidia con sus arquitecturas y tecnología, sin embargo se sobreentiende que AMD-ATI anda por caminos paralelos explorando alternativas similares y hasta equivalentes si bien desde perspectivas algo diferentes o utilizando conceptos distintos (para no ser injusto agregue al final apuntes sobre lo que está haciendo esta compañía). Sin menospreciar la relativa ventaja técnica que posee por contar con el equipo de ATI y su demostrada experiencia y capacidad en el desarrollo de arquitecturas de GPU.
 |
 |
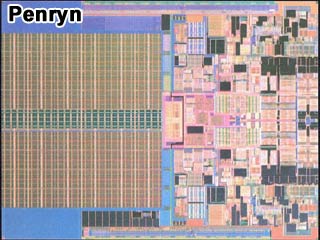
| La primera imagen compara un Pentium con los nuevos procesadores 45nm, con el detalle adicional que un Pentium tenía cosa de 3,1 millónes de transistores y el Penryn ronda los 410 millónes en su versión de dos cores. |
Hace poco Intel confirmo sus planes inmediatos para los próximos cuatro a seis años, los cuales son muy prometedores pero no están libres de riesgo. Todo gira alrededor de cómo planean evolucionar (tal vez revolucionar) el concepto multi-core. Cuando analicé las posibilidades que existen gracias a la tecnología multi-core quedaba claro que un incremento progresivo y casi lineal del número de núcleos sonaba como una idea demasiado simplista y poco efectiva a corto plazo. Con el anuncio oficial sobre la nueva familia de procesadores cuya denominación en código es Nehalem para el 2008, y la todavía más avanzada Sandy Bridge (antes Gesher) con Westmere (antes Nehalem-C, paso a 32nm) entre ambos. Donde todavía abunda confusión es sobre su producto denominado Larrabee planeado para 2009-2010 con posible más información a finales de este año[1].
La motiviación que tiene Intel para el desarrollo y diseño de sus nuevas microarquitecturas es por demás obvia, inevitable y aceptada (también afecta a AMD-ATI)[2], además no hay que olvidar que los modelos que ven la luz de manera pública ahora tienen como mínimo una década en diseño, planificación y desarrollo. No son resultado de caprichos, no son cosas hechas de manera arbitraría. El único factor que se puede ver como incierto es que estén basados en expectativas presentes del mercado, la industria y los usuarios que fueron hechas, originalmente, hace al menos diez años atrás cuando no 15 o más.
Esta búsqueda por nuevas microarquitecturas se hace mucho más importante con el gran salto del siglo XXI: el paso de una mentalidad single-core a multi-core y la necesidad de aprovechar al máximo y de la manera más eficiente posible, tanto empírica como comercialmente, un cada vez mayor número de núcleos de procesamiento; lo que no es tarea fácil.
Aquí es necesario recalcar que ningún tipo de software puede ser diseñado con la habilidad de aprovechar al 100% un número creciente de cores, al igual que existe una frontera en su habilidad de trabajar con lógicas multi-hilo y ser programado para emplear ejecución en paralelo de los mismos[3]. Este límite es dado por muchos factores, entre ellos la imposibilidad que tienen ciertas tareas de ser realizadas de manera concurrente[4], también está el hecho de que las ventajas de la ejecución simultánea en tiempo real no siempre compensan por la dificultad agregada de programarlo (y mantenerlo).
La pregunta que responde Intel con sus nuevas arquitecturas es simple, ¿qué hacer con cada vez más núcleos? (¿y transistores?). Su respuesta es quizá la primera aceptada y lógica en relación al casi utópico sueño de ofrecer el Sistema-en(un)-Chip. A medida que se empieza a tener más y más cores de procesamiento los mismos dejan de ser --todos-- multipropósito y se van especializando. Más allá de la potencial oferta SEUC para el cada vez más grande mercado portatil está la otra alternativa inmediata, el CPU/GPU. El inverso de esto es el GPGPU (General Purpose Graphics Processing Unit, Unidad de Procesamiento Gráfico de Propósito General) una arquitectura de procesador gráfico adaptada, o extendida, para la realización de otras tareas no afines a su razón de ser.
 |
 |
Una representación del chip de un Core2 Duo de la familia Penryn con su diagrama y empaquetadura. A su lado el diagrama del circuito impreso. |
Combinar aptitudes de procesamiento generales (para todo uso) unidas a funciones específicas de manipulación de polígonos y renderizado gráfico ha sido una alternativa buscada desde los primeros días de los engines 3D, los resultados lo fueron todo menos interesantes como lo demuestra su ausencia en la actualidad. Claro que en ese entonces, hace poco más de una década, todo tenía que suceder en un único "procesador general y gráfico", el cambio de escenario hoy en día es que se puede hablar de un "procesador con núcleos generales y/o núcleos gráficos" que a pesar de las similitudes sintácticas son alternativas muy distantes en cuanto a tecnología.
En este punto vale tocar el tema de que los GPU actuales (de AMD-ATI o Nvidia) no son otra cosa que un gran número de núcleos altamente especializados, donde su cantidad en el chip se debe a decisiones de arquitectura propias de cada compañía. Por ejemplo aún no hay ninguna explicación, ni oficial ni comentario, sobre porque las de AMD-ATI poseen hasta casi el triple de los denominados stream cores (que no son otra cosa que los núcleos que pueden trabajar shaders de píxel, vértice o geométricos)[5] y aún así el rendimiento de las tarjetas de una y otra empresa es casi idéntico.
La lógica aquí es que --ahora-- no existe un limitante tecnológico real que impida incluir en un CPU de cuatro cores uno que básicamente sea nada más ni menos que equivalente a un chip de GPU. La ventaja inmediata es que al compartir buses y memoria podrían manipular mucho mejor las imágenes y su renderizado, esto bajo la idea básica de que un CPU procesa lógica, estado y física, y un GPU estado, imagen y renderizado (obviamente hablando de videojuegos). Como comenta Alex St. John, "[p]ara lograr un verdadero avance en los engines dinámicos e interactivos con sistemas de física se requiere conocer el estado de todo lo que entra y sale para procesar la imagen".
El ejemplo más sencillo para dar algo de contexto a lo anterior es hablar del lanzamiento de una granada y su explosión en medio de un grupo de entes virtuales. Lo que teníamos hasta hace poco era una explosión sin esquirlas, sin más consecuencia que el efecto visual del boom. El PhysX de Ageia permite ir un paso más adelante al trabajar con restos sólidos de la granada y procesar sus trayectorias e impacto en algunos de los objetos que le rodean.
El siguiente paso que sería viable es no sólo procesar el efecto inmediato de los fragmentos sino el efecto en cadena que se produciría en un ambiente lleno de objetos capaces de dar una respuesta dinámica, es decir, los cortes sobre la "ropa", las heridas sobre el "cuerpo", la reacción de cada "cuerpo" ante la explosión y la diferencia de fuerza con que les impacta, la caída de cada "cuerpo" y la reacción de cualquier elementos sobre el que cae (cajas, suelo, agua, ventana de un auto), etcétera. Obviamente, en la realidad de lo práctico, aún éste tercer caso estaría acotado, más allá de por los límites de procesamiento por el poco aporte real que tendrían ciertas acciones y reacciones para la experiencia del jugador (p. ej. uno de los "cuerpos" cae sobre un charco de agua y ésta crea una ola pequeña que empuja a una botella... eh... umm... ¿y qué?).
Antes de continuar en este punto permítanme abrir un pequeño paréntesis para contextualizar una idea que se hace recurrente luego. No obstante que hoy en día las conocemos como Tarjetas Gráficas en sus orígenes se las denomino Aceleradoras Gráficas, nombre que era más afin a su función específica. Eso de aceleradoras viene del hecho de que en ese entonces existían engines gráficos que venían con modo software o hardware, el primero aprovechaba del poder de procesamiento adicional de la nueva generación de CPU (486, Pentium, Pentium II) y el segundo de la presencia de hardware especializado para acelerar las operaciones afines al engine gráfico.
La virtual muerte --en ese entonces-- de los engines gráficos basados en software (o con modo software) se debe a: (1) cuestiones del momento no fácilmente diferenciables, (2) condiciones del mercado, (3) el sorpresivo salto evolutivo y tecnológico dado por los GPU, y (4) la entrada en escena del Windows 95 y el DirectX.
El punto es, aunque acepto que hay espacio para discusión, que la necesidad que tenemos hoy en día de las Tarjetas Gráficas no es más que una imposición indirecta, algo nacido artificialmente, algo adoptado y aceptado porque a la velocidad a la que hoy la tecnología avanza no deja mucho tiempo para pensar, o decidir si hay o no mejores caminos, u opciones, en particular desde el punto de vista del usuario que tiene poca voz y voto.
Ahora bien, se puede argumentar que su entrada en escena nos ha permitido llegar al nivel de realismo visual con que gozamos, pero su ausencia muy bien podría sólo haber retrasado las cosas (por ejemplo que estemos ahora con DirectX 8.0 en vez del DirectX 10 pero por software). Es decir, no se trata de algo indispensable, y no existe ningún motivo ni práctico ni teórico para que dada la coyuntura no se vean reemplazadas por equivalentes dentro el paradigma multi-core que vivimos, y viviremos. Ahora cerremos paréntesis.
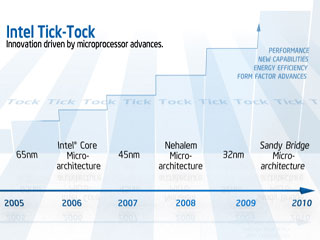 |
| Diagrama representativo de la lógica Tick-Tock de evolución continua de Intel. |
Con el fin de dar rienda suelta a su equpipo de relaciones públicas, porque otra razón no creo que exista, viene al caso describir lo que en el sitio Web de Intel denominan como The Tick-Tock Model of Architecture & Silicon Cadence. La idea es que todo el proceso de desarrollo y producción para los ojos del mercado y los usuarios se divide en dos etapas, el Tick y el Tock (en un cíclo infinito de un año entre uno y otro). El Tick representa el paso a un nuevo sistema de manufactura de aquellas arquitecturas ya en venta, quizá con leves mejoras pero sin mayores extras. Por su lado el Tock introduce nuevas microarquitecturas que incluyen extensiones y medianas o grandes novedades de diseño y tecnología. El más reciente Tick le corresponde a la familia Penryn de Core2-Duo y Core2-Quad que aprovechan de las nuevas plantas de fabricación basadas en 45nm.
Nehalem es la siguiente familia de procesadores en el plan de Intel y corresponde al Tock. La arquitectura de Nehalem es dynamically scalable (lit. escalable dinámicamente) y design-scalable (lit. escalable en diseño), esto quiere decir que en tiempo de ejecución máximiza su rendimiento, y que durante diseño se puede manipular a gusto la presencia de núcleos, cachés, capacidades de interconexión, controladores de memoria e incluso un controlador o complemento gráfico integrado. Esto permite a Intel "ensamblar" diferentes modelos enfocados a distintos sectores del mercado (servidores, estaciones de trabajo, PC y laptops).
Otra característica destacada de Nehalem es su uso de la arquitectura de bus QuickPath Interconnect (antes CSI, Common System Interconnect o Interface) que reemplaza al tradicional FSB (Front Side Bus). Esta tecnología encara uno de los grandes y persistentes problemas de un CPU, la gestión y acceso a memoria e I/O. Si bien esta tecnología no es del todo nueva, ya ha sido utilizada con éxito en servidores y workstations, su presencia integrada en un procesador multi-core si lo es. Su diseño obedece a una lógica punto-a-punto con optimizacions de anillo.
 |
 |
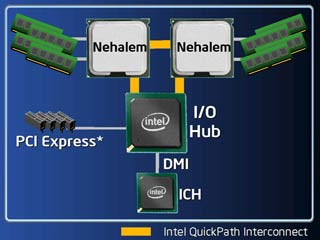
| Diagramas que permiten notar cómo se conecta el bus QPI a los diferentes componentes de una tarjeta madre. El primero trabaja con dos CPU Nehalem y el segundo con cuatro, aquí se nota mejor la lógica anillo del nuevo bus. |
La mejor manera de visualizar las diferencias es que con FSB cualquier acceso a memoria o I/O requiere de "pedir permiso" (lo que podría poner una solicitud en cola) y hacer uso de un único canal disponible, mientras que el QuickPath Interconnect (o QPI) ofrece caminos punto-a-punto entre todos los componentes involucrados y mientras no se requiera utilizar el mismo canal se puede tener varias transmisiones ocurriendo de manera simultánea.
Para aprovechar QPI al máximo Nehalem permite que cada core de procesamiento posea su propio bloque de memoria "privada", la que puede ser accedida por cualquier otro núcleo a través de los canales del nuevo bus. Ambos conceptos ayudan a optimizar y dinamizar la ejecución de aplicaciones multi-hilo y procesos en paralelo reduciendo al máximo el tiempo muerto y evitando los cuellos de botella más críticos en estos casos como son el acceso a RAM y la espera por datos desde periféricos de entrada/salida o el envío de información a los mismos.
La última característica que vale nombrar de esta microarquitectura de Intel es la inclusión de nuevas instrucciones, denominadas en su conjunto SSE4 (Streaming SIMD Extensions 4[6]); de hecho estas se introducen con la familia Penryn, un total de 47, a las que se añade 7 más enfocadas a la optimización y aceleración de los procesos multimedia como ser gestión de audio, imagen (incluyendo gráficos 3D) y texto. Otras instrucciones tienen como objetivo acelerar ciertos procesos con números de punto flotante (números reales).
Si bien la lista de novedades para la pronta a estrenar arquitectura es aún más larga el resto ya no es tan espectacular desde el punto de vista de un usuario: algoritmos --en hardware-- más efectivos y eficientes para la ejecución de aplicaciones y código binario, mayor paralelismo, multi-hilo simultáneo, mejoras a la Caché Inteligente de Intel, menor consumo de energía, menor producción de calor, tamaño reducido, ya no usa plomo.
 |
| Diagrama del circuito impreso de un procesador Nehalem de cuatro cores. Se puede notar como las cachés ocupan una buena parte del chip. |
En paralelo con los respectivos avances para CPU Intel está trabajando en su iniciativa de Computación Visual (Visual Computing) que incluye diversas áreas y tecnologías enfocadas en en la entrega de una mejor experiencia gráfica para el usuario. Esto incluye al mercado de los videojugadores y otros que también pueden aprovechar de gráficos 3D como la medicina, simulación, desarrollo industrial y afines. La gran novedad aquí será la arquitectura Larrabee y su wide SIMD vector processing unit o VPU.
El próximo Tock viene de mano de la familia denominada Sandy Bridge y esta basada en las ideas utilizadas en Nehalem pero llevándolas a un siguiente nivel de sofisticación, además utilizaría el método de fabricación de 32nm. Este salto tiene en parte mucho que ver con las nuevas ideas y conceptos utilizados por el equipo de diseño, investigación y desarrollo, como el incluir núcleos de soporte especializados según el segmento de mercado al que apunta un modelo determinado.
Lo más notable de Sandy Bridge es que se trata de la primera familia en incluir un nuevo conjunto de instrucciones denominadas AVX (Advanced Vector Extensions, Extensiones Avanzadas de Vector), que en los comentarios e información encontrada se le considera como "SIMD en esteroides". Si un SIMD común de 128bits puede manejar 4 números reales de precisión simple o 2 de precisión doble el AVX trae la capacidad de duplicar estas cifras, acelerando la entrega de resultados y ahorrando energía. Este hecho es relevante al tratar multimedia, operaciones con números de punto flotante, engines 3D y vectores (que sucede son la base para el método Ray Tracing de renderizado).
|